仮名漢字変換ログを用いた言語処理の精度向上
概要
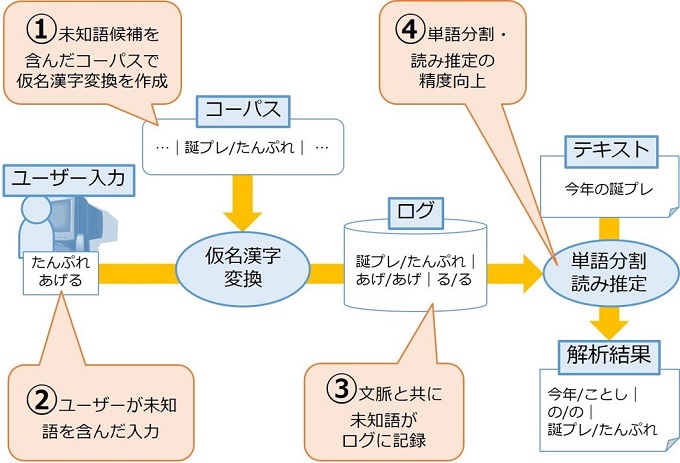
単語分割・読み推定の課題として、未知語の多いテキストを頑健に解析できないという問題がある。本研究ではこの問題に対処するために、文章を作成するときに用いる仮名漢字変換のログを参照する方法を提案する。仮名漢字変換ログとは、インプットメソッドで文章を作成するときの履歴であり、単語境界や入力記号列の情報を含んでいるため、アノテーションデータと見なすことができる。一方で変換ログは、誤った確定結果などを含むためノイズありのアノテーションデータだといえる。本論文では、ノイズを含んだアノテーションデータを学習データに利用する3つの方法を提案する。実験では、Twitterを題材として提案手法を評価し、単語分割・読み推定ともに精度が向上することを確認し、提案手法の有効性を示した。
産業界への展開例・適用分野
あらゆる企業などのコミュニティには、固有名詞などの特有の単語が現れる。本研究で提案する手法を用いて、そのコミュニティの文書作成の際の仮名漢字変換ログを活用することで、単語分割や読み推定の精度が向上する。その結果、コミュニティ内の文書に対する検索やテキストマイニングの精度向上が期待できる。また、本研究の実験のように、マイクロブログに対する解析精度の向上は、マイクロブログを応用した商品のマーケティングなどに貢献することが期待される。
研究者
| 氏名 | 専攻 | 研究室 | 役職/学年 |
|---|---|---|---|
| 高橋 文彦 | 知能情報学専攻 | メディアアーカイブ分野 河原研究室 | 修士2回生 |
| 森 信介 | 学術情報メディアセンター | メディアアーカイブ分野 河原研究室 | 准教授 |
| 笹田 鉄郎 | 学術情報メディアセンター | メディアアーカイブ分野 河原研究室 | その他教職員 |