対数尤度ベクトルを特徴量とし、そのユークリッド距離がKLダイバージェンスを近似する性質を利用して、1000以上の言語モデルを共通空間に埋め込む「言語モデル地図」を構築した。この地図では、モデル性能や得意分野など、多様な「個性」の分布を可視化できる。また、対数尤度の分散に基づく再サンプリングによって、必要なテキスト数を大幅に削減しつつ距離推定精度を維持できることを示した。これにより、大規模なモデル比較をより効率的に実現する。
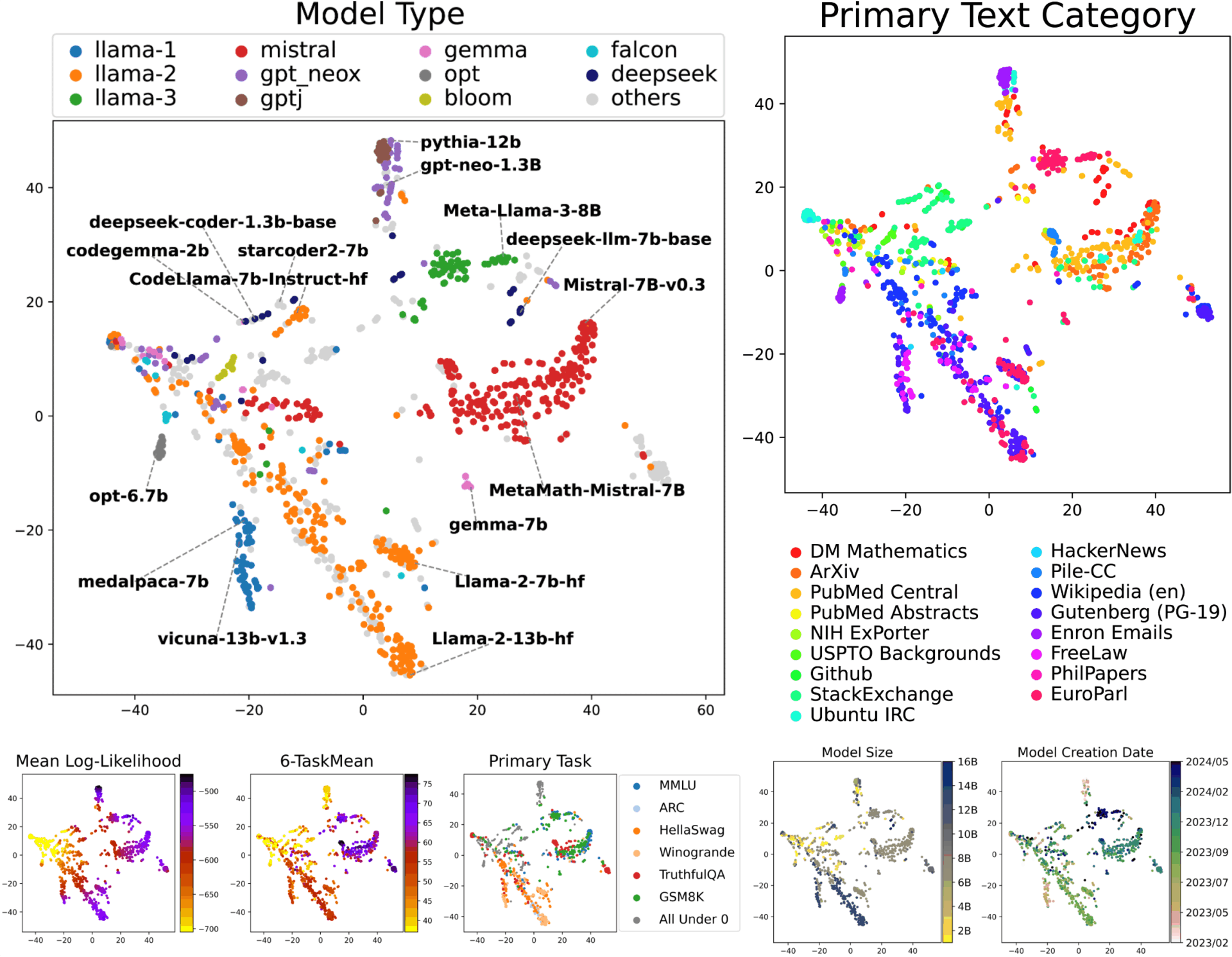
本手法は、多数の言語モデルを共通空間で比較できるという特性から、産業分野でも幅広い応用が期待できる。たとえば、特定タスクやドメインに最適なモデルを選択する際に、モデル間の位置関係を手掛かりとして有望な候補を効率的に絞り込むことができる。また、独自のコーパスに合わせたモデル学習や蒸留の際には、学習過程でのモデル変化を地図上で追跡することで、改善方向や性能の伸びしろを直感的に把握できる。さらに、医療や金融など多様なドメインごとに、モデルの挙動や得意領域を比較評価する土台となる。
| 氏名 | コース | 研究室 | 役職/学年 |
|---|---|---|---|
| 大山百々勢 | システム科学コース | 統計知能分野 | 博士2回生 |
| 岸野稜 | システム科学コース | 統計知能分野 | 修士1回生 |
| 高瀬侑亮 | --- 未設定 | 統計知能分野 | 博士1回生 |
| 山際宏明 | --- 未設定 | 統計知能分野 | 助教 |
| 下平英寿 | --- 未設定 | 統計知能分野 | 教授 |