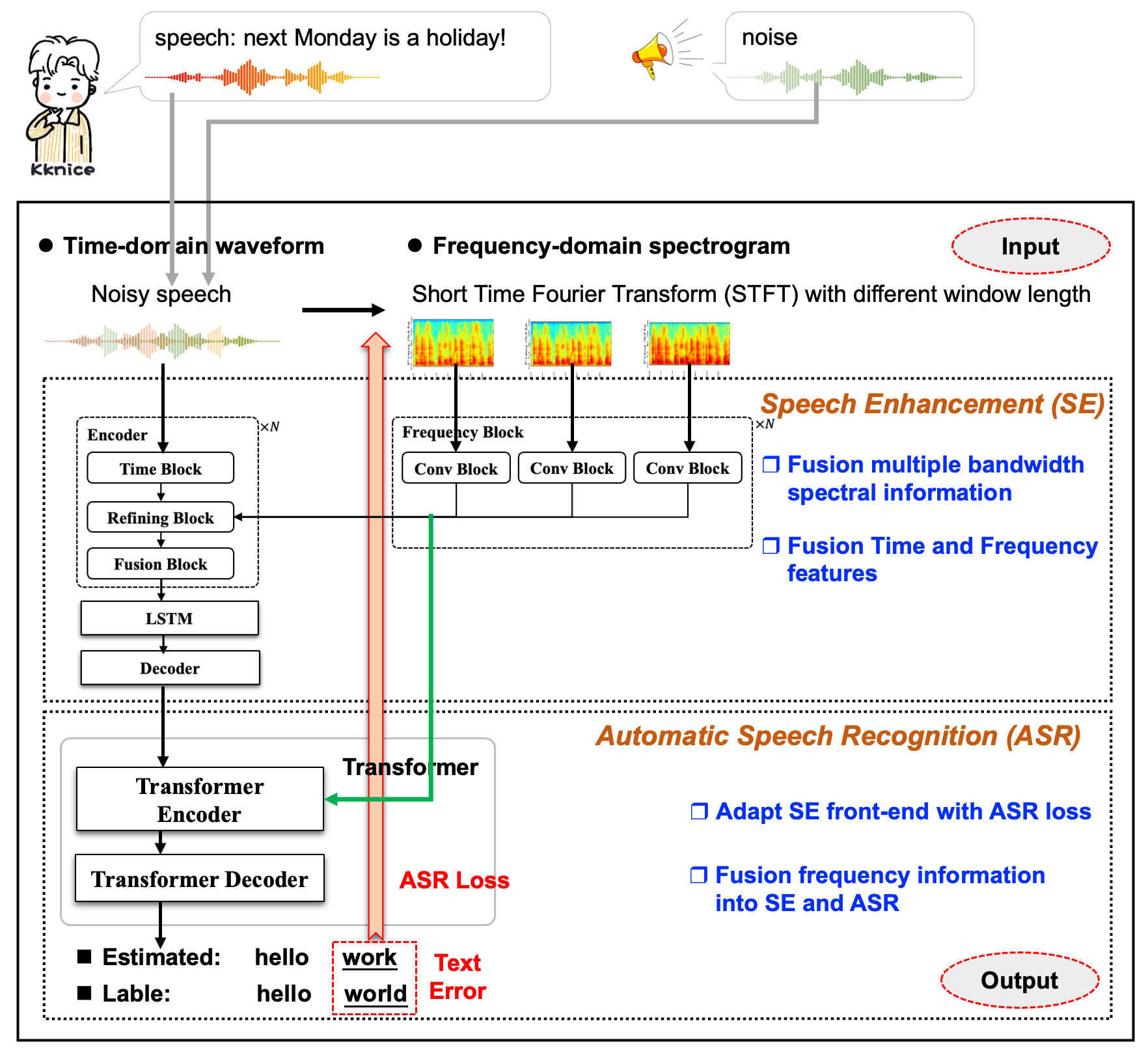
While waveform-domain speech enhancement (SE) has been extensively investigated in recent years and achieves state-of-the-art performance in many datasets, spectrogram-based SE tends to show robust and stable enhancement behavior. In this work, we propose a waveform-spectrogram hybrid system (WaveSpecEnc) to improve the robustness of waveform-domain SE. WaveSpecEnc refines the corresponding temporal feature maps by spectrogram encoding in each encoder layer. Incorporating spectral information can provide robust human hearing experience performance. However, WaveSpecEnc has a minor automatic speech recognition (ASR) improvement. Thus, we improve the WaveSpecEnc for robust ASR by further utilizing spectrogram encoding information (WaveSpecEnc+). WaveSpecEnc+ supplements encoding information to both the SE front-end and ASR back-end.
speech and audio processing
| 氏名 | コース | 研究室 | 役職/学年 |
|---|---|---|---|
| Hao SHI | 知能情報学コース | Speech and Audio Processing Lab. | 博士3回生 |
| Tatsuya Kawahara | 知能情報学コース | Speech and Audio Processing Lab. | 教授 |