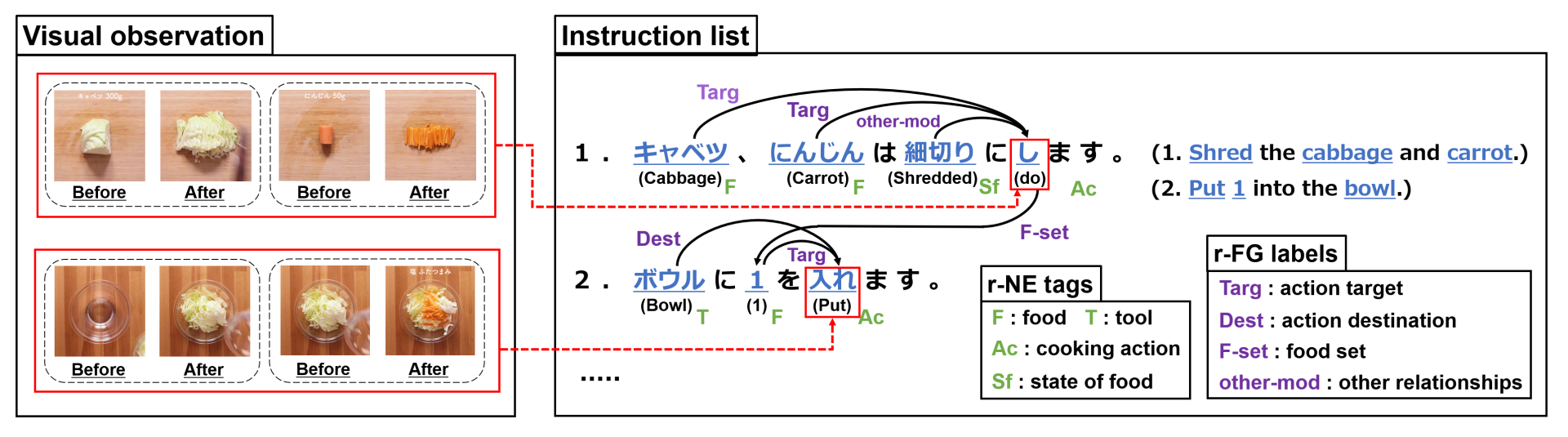
We present a new multimodal dataset called Visual Recipe Flow, which enables us to learn each cooking action result in a recipe text. The dataset consists of object state changes and the workflow of the recipe text. The state change is represented as an image pair, while the workflow is represented as a recipe flow graph (r-FG). The image pairs are grounded in the r-FG, which provides the cross-modal relation. With our dataset, one can try a range of applications, from multimodal commonsense reasoning and procedural text generation.
調理ロボットの実現等.
| 氏名 | 専攻 | 研究室 | 役職/学年 |
|---|---|---|---|
| 白井 圭佑 | 知能情報学専攻 | テキストメディア | 博士3回生 |
| 橋本 敦史 | その他: その他 | その他: その他 | |
| 西村 太一 | 知能情報学専攻 | テキストメディア | 博士3回生 |
| 亀甲 博貴 | 学術情報メディアセンター | 大規模テキストアーカイブ研究分野 | 助教 |
| 栗田 修平 | その他: その他 | その他: その他 | |
| 牛久 祥孝 | その他: その他 | その他: その他 | |
| 森 信介 | 学術情報メディアセンター | 大規模テキストアーカイブ研究分野 | 教授 |