Reinforcement learning (RL) considers settings in which an agent makes a sequence of decisions. Take robot navigation as an example. To reach goal position, an agent needs to make a sequence of decisions; each decision involves its current location and its next movement. RL is concerned with learning a function that outputs a movement given its current location. Beside robotics, RL also finds application in domains such as game AI, recommender systems and trading. Meanwhile, the standard setting for RL requires a function called the reward function, which is used for evaluating the agent's decisions. The design of this function is in fact a challenge for real-world applications, because it requires expertise for both RL and the corresponding task. To address this challenge, this project considers learning a reward function from human preferences, which are qualitative feedback about how well the agent solves the task. In particular, this project has investigated the utilization of noisy preferences from non-expert annotators and the interpretability of the learned reward function. Techniques developed in this project can expand the application of RL, especially to areas in which the agent needs to comply with humans.
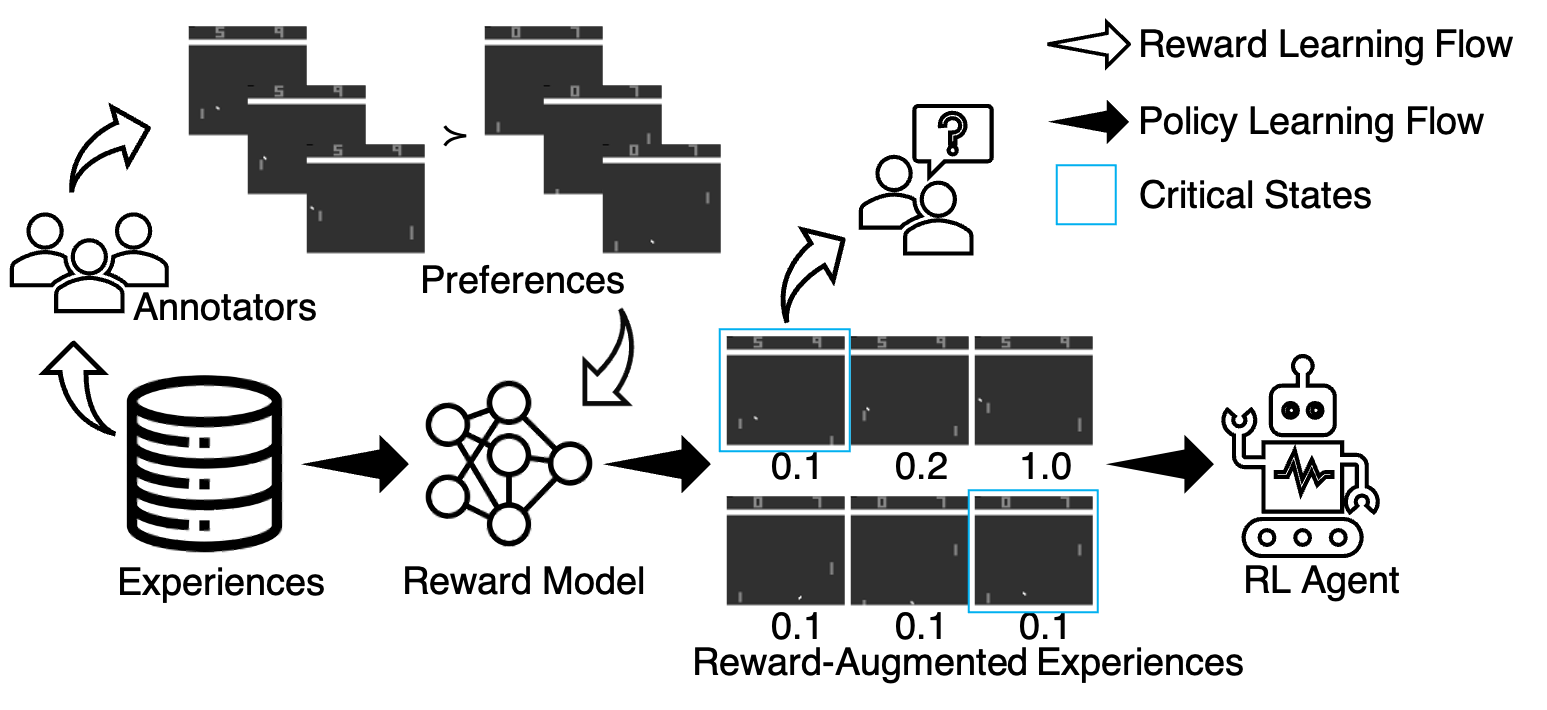
Techniques developed in this project can be used for human-in-the-loop applications. An agent can acquire desirable behaviors and skills by learning from humans.
| 氏名 | 専攻 | 研究室 | 役職/学年 |
|---|---|---|---|
| Zhang Guoxi | 知能情報学専攻 | 鹿島・山田研究室 | 博士3回生 |
| 鹿島久嗣 | 知能情報学専攻 | 鹿島・山田研究室 | 教授 |