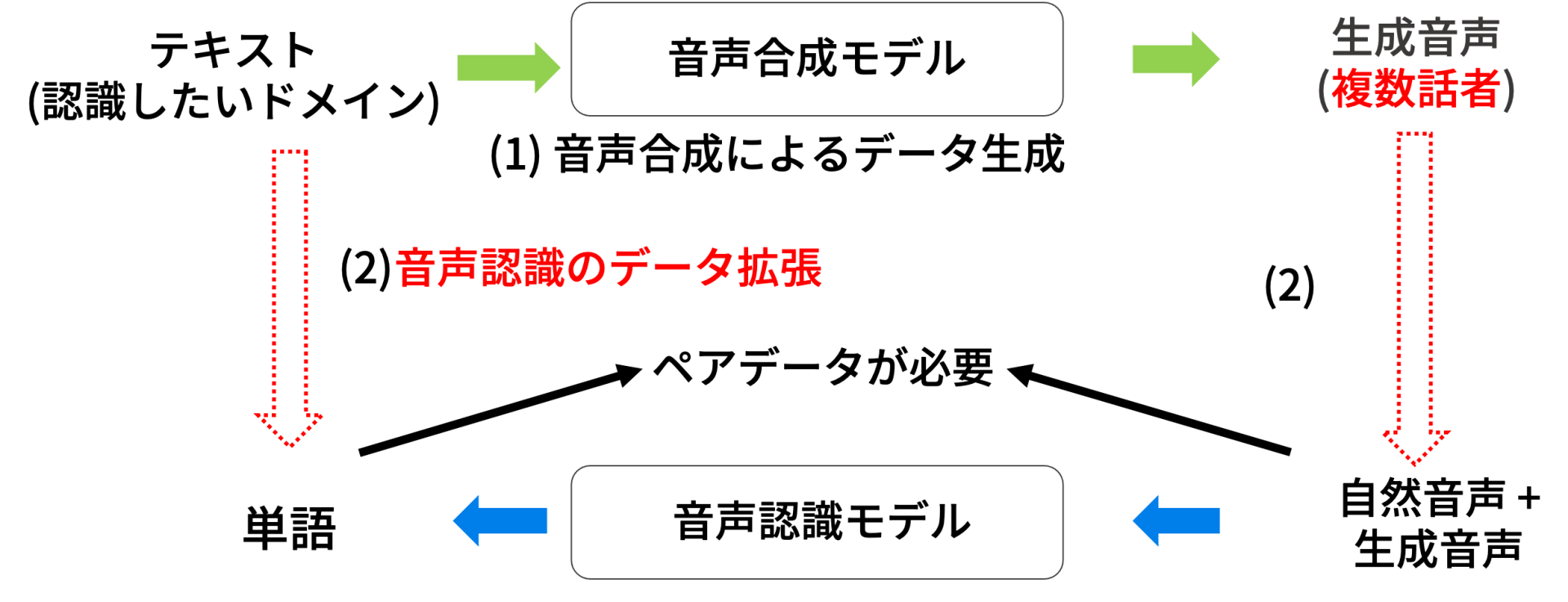
音声認識は音声から話した内容(単語)を書き起こす問題であるが,近年ニューラルネットワークの発展により簡潔なモデルで高速で高精度な認識が可能になった.しかし,そのモデルの訓練データは音声と書き起こしのペアデータであり,その訓練データを多量に必要とするという問題と,認識したいドメインのペアデータの準備が困難であるという問題が存在する.そこで本研究では,音声合成を用いた音声認識の訓練データの生成を行う.具体的には (1) 音声合成モデルを用いて任意のテキストから生成を行い,(2)生成された音声と自然音声を用いて音声認識の学習を行う.実験結果から,ペアデータの手に入らない未知のドメイン(話題・テーマ)の音声認識タスクにおいて,自然音声にとって未知の単語の認識等、音声認識の改善に効果的であることを示した.
- 専門用語などに頑健な音声認識システム
- ユーザに合わせた音声認識システムの構築
| 氏名 | 専攻 | 研究室 | 役職/学年 |
|---|---|---|---|
| 上乃聖 | 知能情報学専攻 | 河原研究室 | 博士3回生 |