スマートスピーカや対話ロボットなどは注目話者がマイクから離れた位置で発話する場合があり,マイクでの観測音に雑音が含まれてしまい音声認識を行うことが困難となる.このような状況において,観測音を各音源の信号に分離することによって音声認識率を向上させることを目的としている.我々は観測される多チャネル混合音の統計的生成モデルを定式化し,観測音が得られた際に逆問題を解くというアプローチをとることで,教師有り学習とは異なり事前学習が不要で,様々な環境で頑健に動作する手法を開発した.
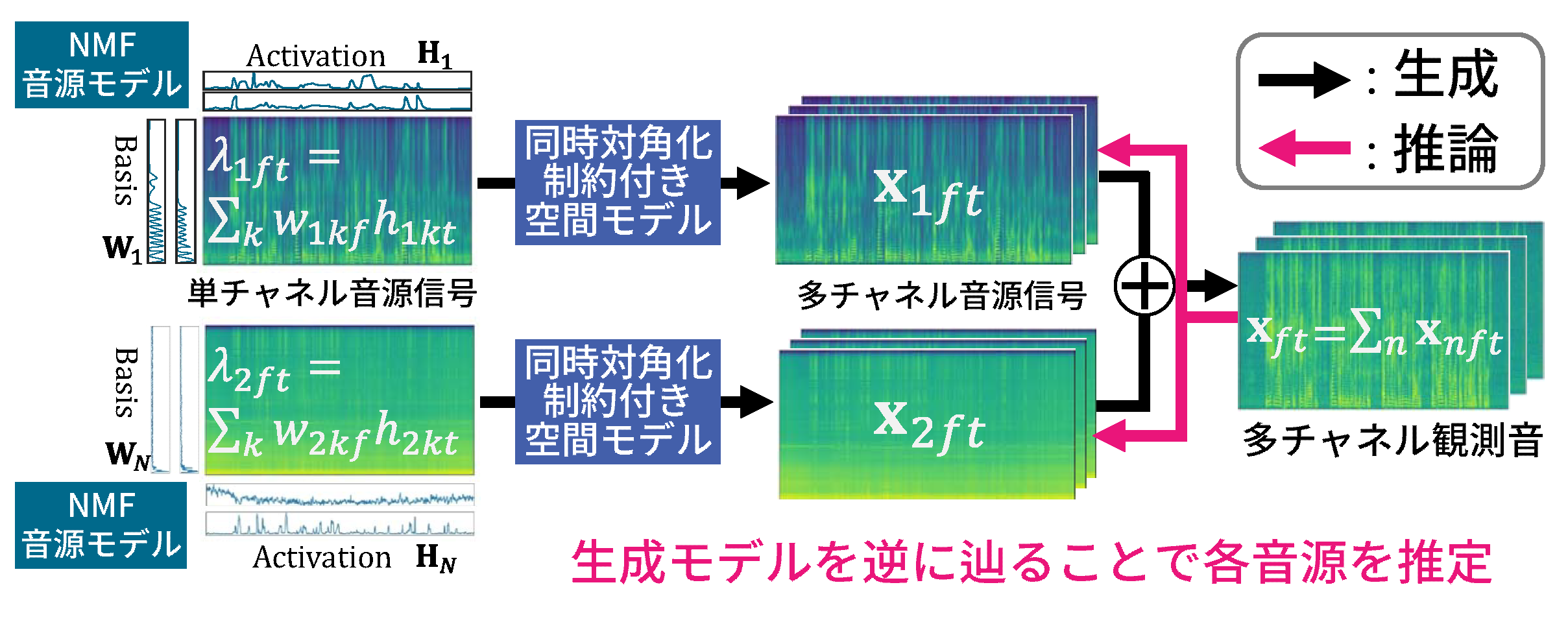
・スマートスピーカや対話ロボットなどの音声認識を用いるシステム
・音声を聞き取りやすくするための聴覚補助システム
| 氏名 | 専攻 | 研究室 | 役職/学年 |
|---|---|---|---|
| 関口航平 | 知能情報学専攻 | 河原研究室 | 博士3回生 |